Canarim-Bert-Nheengatu

Sobre
O modelo canarim-bert-posTag-nheengatu é um modelo de marcação de classe gramatical para a língua Nheengatu que foi treinado no conjunto de dados UD_Nheengatu-CompLin disponível no github. Foi utilizado como base o tokenizador e o modelo Canarim-Bert-Nheengatu.
Etiquetas Suportadas
O modelo é capaz de identificar as seguintes classes gramaticais:
| etiqueta | abreviatura no glossário | expansão da abreviatura |
|---|---|---|
| ADJ | adj. | adjetivo de 1ª cl. |
| ADP | posp. | posposição |
| ADV | adv. | advérbio |
| AUX | aux. | auxiliar |
| CCONJ | cconj. | conjunção coordenativa |
| DET | det. | determinante |
| INTJ | interj. | interjeição |
| NOUN | n. | substantivo de 1ª classe |
| NUM | num. | numeral |
| PART | part. | partícula |
| PRON | pron. | pronome de 1ª classe |
| PROPN | prop. | substantivo próprio |
| PUNCT | punct. | pontuação |
| SCONJ | sconj. | conjunção subordinativa |
| VERB | v. | verbo de 1ª classe |
Treinamento
Conjunto de Dados
O conjunto de dados utilizado para o treinamento foi o UD_Nheengatu-CompLin, dividido na proporção 80/10/10 para treino, avaliação e teste, respectivamente.
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'pos_tags', 'text'],
num_rows: 1068
})
test: Dataset({
features: ['id', 'tokens', 'pos_tags', 'text'],
num_rows: 134
})
eval: Dataset({
features: ['id', 'tokens', 'pos_tags', 'text'],
num_rows: 134
})
})Hiperparâmetros
Os hiperparâmetros utilizados para o treinamento foram:
learning_rate: 3e-4train_batch_size: 16eval_batch_size: 32gradient_accumulation_steps: 1weight_decay: 0.01num_train_epochs: 10
Resultados
A perca de treinamento e validação ao longo das épocas pode ser visualizada abaixo:
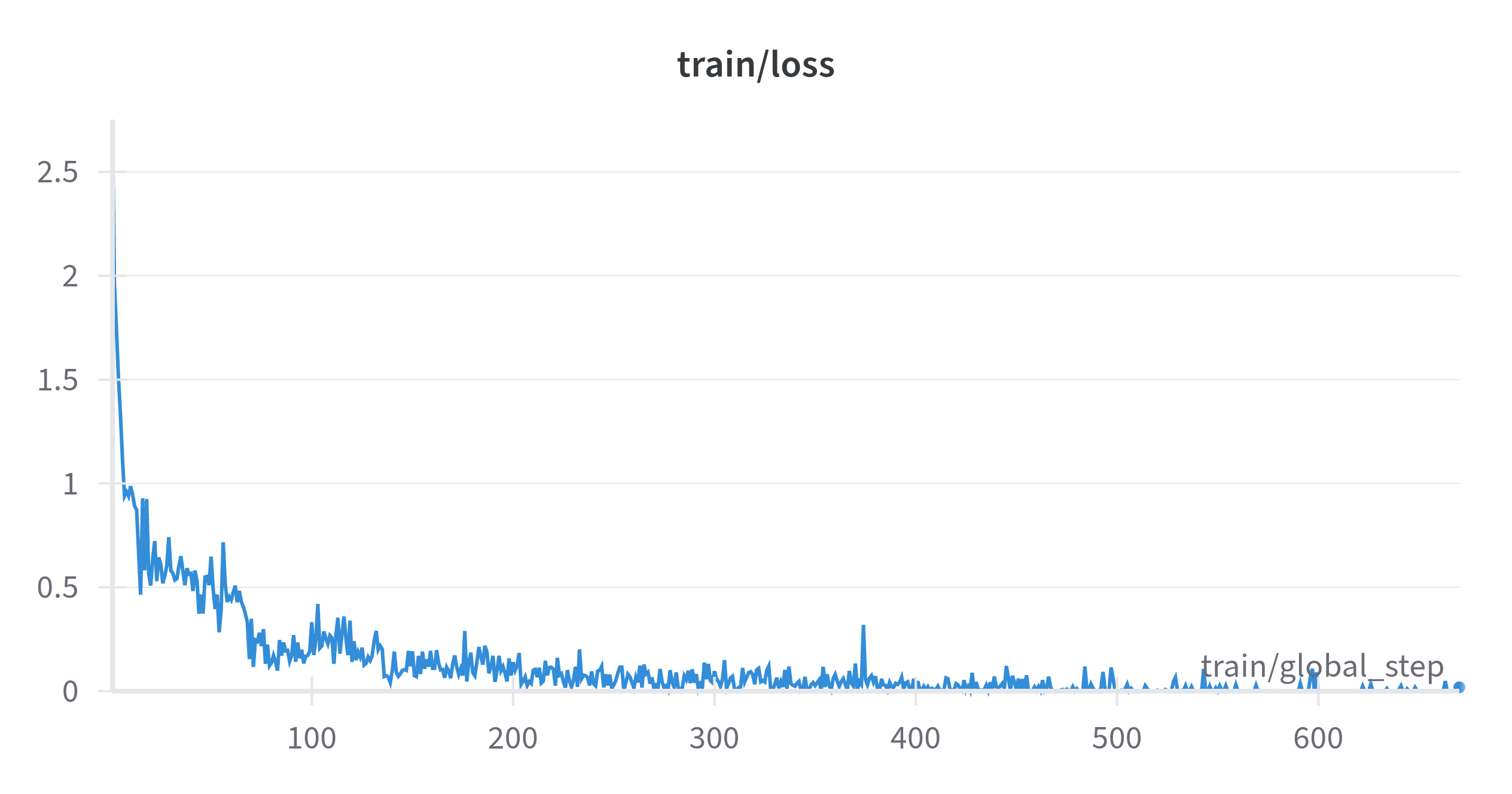
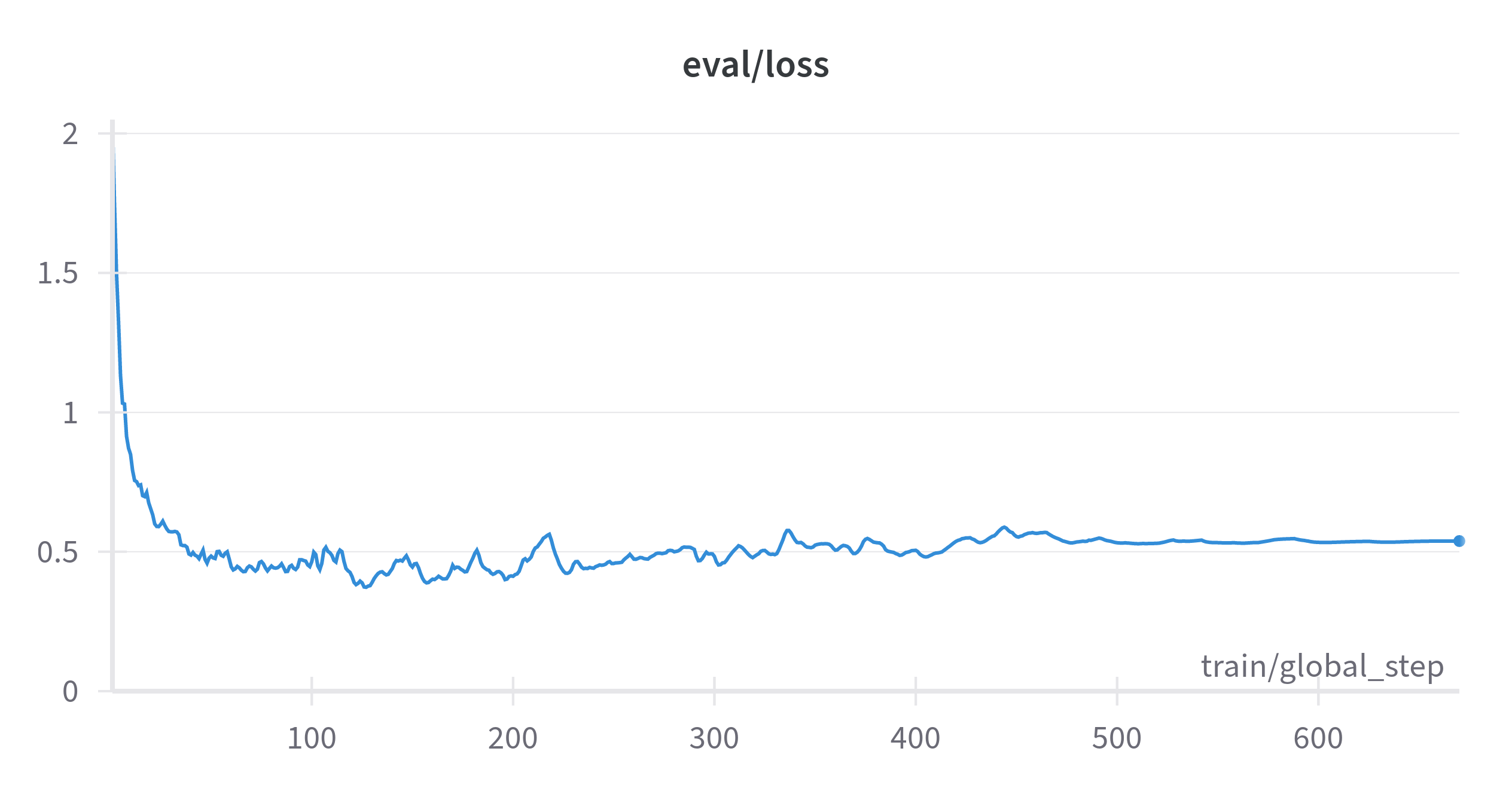
Os resultados do modelo no conjunto de avaliação podem ser visualizados abaixo:
{
'eval_loss': 0.5337784886360168,
'eval_precision': 0.913735899137359,
'eval_recall': 0.913735899137359,
'eval_f1': 0.913735899137359,
'eval_accuracy': 0.913735899137359,
'eval_runtime': 0.1957,
'eval_samples_per_second': 684.883,
'eval_steps_per_second': 25.555,
'epoch': 10.0
}Métricas
As métricas de avaliação do modelo no conjunto de teste podem ser visualizadas abaixo:
precision recall f1-score support
ADJ 0.7895 0.6522 0.7143 23
ADP 0.9355 0.9158 0.9255 95
ADV 0.8261 0.8172 0.8216 93
AUX 0.9444 0.9189 0.9315 37
CCONJ 0.7778 0.8750 0.8235 8
DET 0.8776 0.9149 0.8958 47
INTJ 0.5000 0.5000 0.5000 4
NOUN 0.9257 0.9222 0.9239 270
NUM 1.0000 0.6667 0.8000 6
PART 0.9775 0.9062 0.9405 96
PRON 0.9568 1.0000 0.9779 155
PROPN 0.6429 0.4286 0.5143 21
PUNCT 0.9963 1.0000 0.9981 267
SCONJ 0.8000 0.7500 0.7742 32
VERB 0.8651 0.9347 0.8986 199
micro avg 0.9202 0.9202 0.9202 1353
macro avg 0.8543 0.8135 0.8293 1353
weighted avg 0.9191 0.9202 0.9187 1353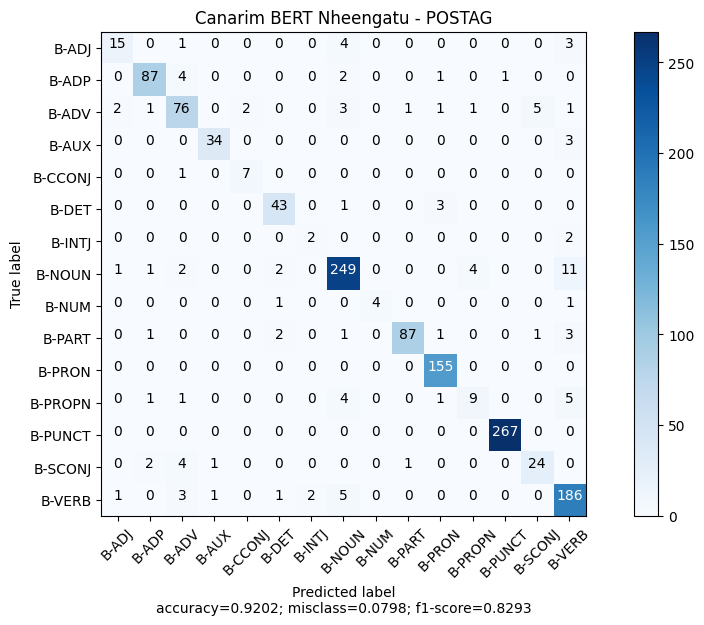
Uso
A utilização deste modelo segue os padrões comuns da biblioteca transformers. Para utilizá-lo, basta instalar a biblioteca e carregar o modelo:
from transformers import pipeline
model_name = "dominguesm/canarim-bert-postag-nheengatu"
pipe = pipeline("ner", model=model_name)
pipe("Yamunhã timbiú, yapinaitika, yamunhã kaxirí.", aggregation_strategy="average")O resultado será:
[
{"entity_group": "VERB", "score": 0.999668, "word": "Yamunhã", "start": 0, "end": 7},
{"entity_group": "NOUN", "score": 0.99986947, "word": "timbiú", "start": 8, "end": 14},
{"entity_group": "PUNCT", "score": 0.99993193, "word": ",", "start": 14, "end": 15},
{"entity_group": "VERB", "score": 0.9995308, "word": "yapinaitika", "start": 16, "end": 27},
{"entity_group": "PUNCT", "score": 0.9999416, "word": ",", "start": 27, "end": 28},
{"entity_group": "VERB", "score": 0.99955815, "word": "yamunhã", "start": 29, "end": 36},
{"entity_group": "NOUN", "score": 0.9998684, "word": "kaxirí", "start": 37, "end": 43},
{"entity_group": "PUNCT", "score": 0.99997807, "word": ".", "start": 43, "end": 44}
]Licença
A licença deste modelo segue a licença do conjunto de dados utilizado para o treinamento, ou seja, CC BY-NC-SA 4.0. Para mais informações, acesse o repositório do conjunto de dados
Referências
@inproceedings{stil,
author = {Leonel de Alencar},
title = {Yauti: A Tool for Morphosyntactic Analysis of Nheengatu within the Universal Dependencies Framework},
booktitle = {Anais do XIV Simpósio Brasileiro de Tecnologia da Informação e da Linguagem Humana},
location = {Belo Horizonte/MG},
year = {2023},
keywords = {},
issn = {0000-0000},
pages = {135--145},
publisher = {SBC},
address = {Porto Alegre, RS, Brasil},
doi = {10.5753/stil.2023.234131},
url = {https://sol.sbc.org.br/index.php/stil/article/view/25445}
}