Whisper Tiny PT - Uma nova abordagem em Reconhecimento Automático de Fala para o Português
O projeto Whisper Tiny PT é uma versão ajustada (fine-tuned) do modelo openai/whisper-tiny com o conjunto de dados Common Voice 11.0. O objetivo deste projeto foi desenvolver um modelo de Reconhecimento Automático de Fala (ASR) especializado em transcrever áudios em português para texto.
O Whisper Tiny PT foi treinado com um conjunto de hiperparâmetros cuidadosamente selecionados e alcançou resultados notáveis na avaliação do conjunto de validação, com um valor de Loss de 0.6077 e um Word Error Rate (WER) de 29.9844.
Sobre o Treinamento
Os hiperparâmetros utilizados no treinamento incluíram uma taxa de aprendizado (learning rate) de 1e-05, um tamanho de lote de treinamento (train_batch_size) de 64, um tamanho de lote de avaliação (eval_batch_size) de 8, e o uso da técnica de treinamento de precisão mista (mixed_precision_training).
O treinamento foi realizado ao longo de 5000 etapas (training_steps), com um agendamento linear (lr_scheduler_type) de aquecimento (warmup) de 500 etapas (lr_scheduler_warmup_steps). Para a otimização do modelo, foi utilizado o otimizador Adam com parâmetros específicos.
Resultados e Contribuições
Durante o treinamento, foram registrados os valores de perda (Loss) e Word Error Rate (WER) em várias etapas. O modelo demonstrou uma melhoria significativa ao longo das etapas, chegando a uma perda de 0.0205 e um WER de 29.9844 ao final do treinamento.
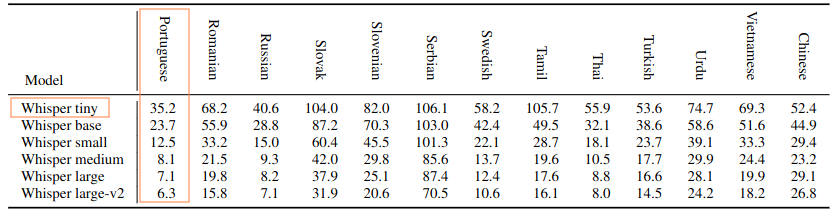
Uma contribuição notável do Whisper Tiny PT é sua superioridade em relação ao modelo Whisper original. A avaliação do modelo utilizando o conjunto de testes do Common Voice 11.0 revelou que o Whisper Tiny PT obteve uma Word Error Rate normalizada (Normalized WER) de 29.9844, enquanto o modelo Whisper original alcançou 35.2 no conjunto de testes do Common Voice 9.0. Essa diferença mostra que o Whisper Tiny PT é mais eficiente em transcrever áudios em português para texto quando comparado ao Whisper original multilíngue.
Sobre o Whisper
O Whisper é um modelo pré-treinado para Reconhecimento Automático de Fala (ASR) e tradução de fala. Ele foi treinado em um conjunto extenso de dados rotulados, totalizando 680.000 horas de áudios, utilizando anotações de supervisão fraca em larga escala.
O modelo Whisper é baseado na arquitetura Transformer, também conhecida como modelo codificador-decodificador (encoder-decoder), e demonstra uma forte capacidade de generalização para diversos conjuntos de dados e domínios sem a necessidade de ajustes finos (fine-tuning).
Conclusão
O projeto Whisper Tiny PT representa uma abordagem inovadora em Reconhecimento Automático de Fala para o idioma português. Ao ajustar o modelo Whisper original em dados do Common Voice 11.0, consegui obter um modelo altamente eficiente para transcrever áudios em português para texto. Os resultados obtidos demonstram a capacidade do modelo de superar a versão original do Whisper Tiny, o que é uma conquista notável para a comunidade de processamento de linguagem natural e Reconhecimento Automático de Fala em língua portuguesa. Com esses avanços, espero que o Whisper Tiny PT possa ser útil em uma ampla gama de aplicações, incluindo transcrição de áudios, assistentes virtuais e muito mais.